Разница между UMA и NUMA

Содержание

Мультипроцессоры можно разделить на три категории моделей с разделяемой памятью - UMA (Uniform Unix Access Access), NUMA (Uniform Un Access Access) и COMA (Доступ к Cache-only Memory). Модели различаются в зависимости от того, как распределены ресурсы памяти и оборудования. В модели UMA физическая память равномерно распределяется между процессорами, которые также имеют равную задержку для каждого слова памяти, в то время как NUMA обеспечивает переменное время доступа для процессоров для доступа к памяти.
Пропускная способность, используемая в UMA для памяти, ограничена, поскольку она использует один контроллер памяти. Основным мотивом появления машин NUMA является увеличение доступной пропускной способности памяти с помощью нескольких контроллеров памяти.
-
- Сравнительная таблица
- Определение
- Ключевые отличия
- Вывод
Сравнительная таблица
| Основа для сравнения | UMA | NUMA |
|---|---|---|
| основной | Использует один контроллер памяти | Контроллер множественной памяти |
| Тип используемых автобусов | Одиночный, множественный и перекладина | Дерево и иерархические |
| Время доступа к памяти | равных | Изменения в зависимости от расстояния микропроцессора. |
| Подходит для | Приложения общего назначения и разделения времени | Приложения реального времени и критичные ко времени |
| скорость | Помедленнее | Быстрее |
| Пропускная способность | Ограниченное | Больше чем УМА. |
Определение UMA
UMA (унифицированный доступ к памяти) Система представляет собой архитектуру разделяемой памяти для мультипроцессоров. В этой модели используется единственная память, к которой обращаются все процессоры представленной многопроцессорной системы с помощью межсоединительной сети. Каждый процессор имеет равное время доступа к памяти (задержка) и скорость доступа. Он может использовать либо одну шину, несколько шин или коммутатор. Поскольку он обеспечивает сбалансированный доступ к общей памяти, он также известен как SMP (Симметричный мультипроцессор) системы.
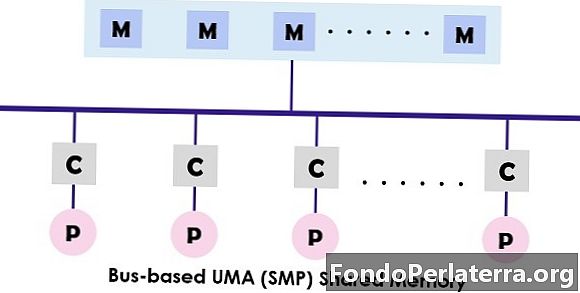
Типичный дизайн SMP показан выше, где каждый процессор сначала подключается к кешу, а затем кеш связывается с шиной. Наконец автобус подключен к памяти. Эта архитектура UMA уменьшает конкуренцию за шину за счет извлечения инструкций непосредственно из отдельного изолированного кэша. Это также обеспечивает равную вероятность для чтения и записи для каждого процессора. Типичными примерами модели UMA являются серверы Sun Starfire, альфа-сервер Compaq и серия HP v.
Определение NUMA
NUMA (неоднородный доступ к памяти) также является многопроцессорной моделью, в которой каждый процессор связан с выделенной памятью. Однако эти небольшие части памяти объединяются в единое адресное пространство. Главное, над чем подумать, это то, что в отличие от UMA время доступа к памяти зависит от расстояния, на котором расположен процессор, что означает изменение времени доступа к памяти. Это позволяет получить доступ к любой ячейке памяти, используя физический адрес.
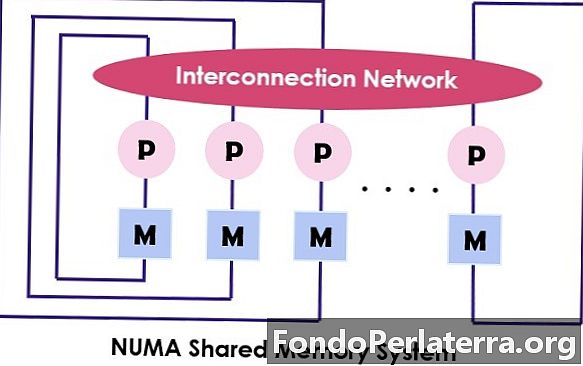
Как упоминалось выше, архитектура NUMA предназначена для увеличения доступной пропускной способности памяти и для которой она использует несколько контроллеров памяти. Он объединяет многочисленные ядра машин в «узлыГде каждое ядро имеет контроллер памяти. Для доступа к локальной памяти на компьютере NUMA ядро извлекает память, управляемую контроллером памяти его узлом. В то время как для доступа к удаленной памяти, которая обрабатывается другим контроллером памяти, ядро запрашивает память через межсоединения.
Архитектура NUMA использует древовидную и иерархическую шинную сети для соединения блоков памяти и процессоров. BBN, TC-2000, SGI Origin 3000, Cray - некоторые из примеров архитектуры NUMA.
- Модель UMA (совместно используемая память) использует один или два контроллера памяти. В отличие от этого, NUMA может иметь несколько контроллеров памяти для доступа к памяти.
- В архитектуре UMA используются одиночные, множественные и перекрестные шины. И наоборот, NUMA использует иерархические и древовидные типы шин и сетевых подключений.
- В UMA время доступа к памяти для каждого процессора одинаково, в то время как в NUMA время доступа к памяти изменяется по мере изменения расстояния памяти от процессора.
- Приложения общего назначения и разделения времени подходят для машин UMA. В отличие от этого, подходящее приложение для NUMA ориентировано в режиме реального времени и критично ко времени.
- Параллельные системы на основе UMA работают медленнее, чем системы NUMA.
- Когда речь идет о пропускной способности UMA, имеют ограниченную пропускную способность. Напротив, NUMA имеет пропускную способность больше, чем UMA.
Вывод
Архитектура UMA обеспечивает одинаковую общую задержку для процессоров, обращающихся к памяти. Это не очень полезно при доступе к локальной памяти, потому что задержка будет равномерной. С другой стороны, в NUMA каждый процессор имел свою выделенную память, которая устраняет задержки при доступе к локальной памяти. Задержка изменяется при изменении расстояния между процессором и памятью (то есть неоднородно). Тем не менее, NUMA улучшила производительность по сравнению с архитектурой UMA.





